Research
I favor a mathematically rigorous approach that cleanly formalizes the intuitions.
My Ph.D. work is on multi-agent machine leanring systems to develop principled methods to enable collaboration of multiple agents in the context of machine learning. I focus specifically in these areas: data-centric machine learning, federated learning, data and model valuation, incentive mechanisms and multi-agent systems.
Selected Publications
* denotes equal contributions.Conference Proceedings
-
Efficient Top-m Data Values Identification for Data Selection .
Xiaoqiang Lin, Xinyi Xu, See-Kiong Ng, Bryan Kian Hsiang Low.
In The Thirteenth International Conference on Learning Representations (ICLR'25), Singapore, Singapore, Apr.25 - 28, 2025.
Acceptance rate (32.08%). Abstract |Code | Cite (Bibtex)
Data valuation has found many real-world applications, e.g., data pricing and data selection. However, the most adopted approach -- Shapley value (SV) -- is computationally expensive due to the large number of model trainings required. Fortunately, most applications (e.g., data selection) require only knowing the data points with the highest data values (i.e., top-$m$ data values), which implies the potential for fewer model trainings as exact data values are not required. Existing work formulates top-$m$ Shapley value identification as top-$m$arms identification in multi-armed bandits (MAB). However, the proposed approach falls short because it does not utilize data features to predict data values, a method that has been shown empirically to be effective. A recent top-$m$ arms identification work does consider the use of arm features while assuming a linear relationship between arm features and rewards, which is often not satisfied in data valuation. To this end, we propose the GPGapE algorithm that uses the Gaussian process to model the \emph{non-linear} mapping from data features to data values, removing the linear assumption. We theoretically analyze the correctness and stopping iteration of GPGapE in finding an $(\epsilon,\delta)$-approximation to the top-$m$ data values. We further improve the computational efficiency, by calculating data values using small data subsets to reduce the computation cost of model trainings. We empirically demonstrate that GPGapE outperforms other baselines in top-$m$ data values identification, noisy data detection, and data subset selection on real-world datasets.
@inproceedings{lin2025_topm, title={Top-m Data Values Identification}, author={Xiaoqiang Lin and Xinyi Xu and See-Kiong Ng and Bryan Kian Hsiang Low}, booktitle={The Thirteenth International Conference on Learning Representations}, year={2025}, url={https://openreview.net/forum?id=lOfuvmi2HT} } -
Data Distribution Valuation .
Xinyi Xu, Shuaiqi Wang, Chuan-Sheng Foo, Bryan Kian Hsiang Low and Giulia Fanti.
In Advances in Neural Information Processing Systems 37: 38th Annual Conference on Neural Information Processing Systems (NeurIPS'24), Vancouver, Canada, Dec. 9-15, 2024.
Acceptance rate (25.8%). Abstract |Code |Poster |Talk | Cite (Bibtex)
Data valuation is a class of techniques for quantitatively assessing the value of data for applications like pricing in data marketplaces. Existing data valuation methods define a value for a discrete dataset. However, in many use cases, users are interested in not only the value of the dataset, but that of the distribution from which the dataset was sampled. For example, consider a buyer trying to evaluate whether to purchase data from different vendors. The buyer may observe (and compare) only a small preview sample from each vendor, to decide which vendor's data distribution is most useful to the buyer and purchase. The core question is how should we compare the values of data distributions from their samples? Under a Huber characterization of the data heterogeneity across vendors, we propose a maximum-mean discrepancy (MMD)-based valuation method which enables theoretically principled and actionable policies for comparing data distributions from samples. We empirically demonstrate that our method is sample-efficient and effective in identifying valuable data distributions against several existing baselines, on multiple real-world datasets (e.g., network intrusion detection, credit card fraud detection) and downstream applications (classification, regression).
@inproceedings{xu2024datadistributionvaluation, title={Data Distribution Valuation}, booktitle={Thirty-eighth Conference on Neural Information Processing Systems}, author={Xinyi Xu and Shuaiqi Wang and Chuan-Sheng Foo and Bryan Kian Hsiang Low and Giulia Fanti}, year={2024}} -
DETAIL: Task DEmonsTration Attribution for Interpretable In-context Learning .
Zijian Zhou, Xiaoqiang Lin, Xinyi Xu, Alok Prakash, Daniela Rus, and Bryan Kian Hsiang Low.
In Advances in Neural Information Processing Systems 37: 38th Annual Conference on Neural Information Processing Systems (NeurIPS'24), Vancouver, Canada, Dec. 9-15, 2024.
Acceptance rate (25.8%). Abstract |Code | Cite (Bibtex)
In-context learning (ICL) allows transformer-based language models that are pre-trained on general text to quickly learn a specific task with a few "task demonstrations" without updating their parameters, significantly boosting their flexibility and generality. ICL possesses many distinct characteristics from conventional machine learning, thereby requiring new approaches to interpret this learning paradigm. Taking the viewpoint of recent works showing that transformers learn in context by formulating an internal optimizer, we propose an influence function-based attribution technique, DETAIL, that addresses the specific characteristics of ICL. We empirically verify the effectiveness of our approach for demonstration attribution while being computationally efficient. Leveraging the results, we then show how DETAIL can help improve model performance in real-world scenarios through demonstration reordering and curation. Finally, we experimentally prove the wide applicability of DETAIL by showing our attribution scores obtained on white-box models are transferable to black-box models in improving model performance.
@inproceedings{zhou2024detailtaskdemonstrationattribution, title={DETAIL: Task DEmonsTration Attribution for Interpretable In-context Learning}, booktitle={Thirty-eighth Conference on Neural Information Processing Systems}, author={Zijian Zhou and Xiaoqiang Lin and Xinyi Xu and Alok Prakash and Daniela Rus and Bryan Kian Hsiang Low}, year={2024}} -
Data-Centric AI in the Age of Large Language Models .
Xinyi Xu, Zhaoxuan Wu, Rui Qiao, Arun Verma, Yao Shu, Jingtan Wang, Xinyuan Niu, Zhenfeng He, Jiangwei Chen, Zijian Zhou, Gregory Kang Ruey Lau, Hieu Dao, Lucas Agussurja, Rachael Hwee Ling Sim, Xiaoqiang Lin, Wenyang Hu, Zhongxiang Dai, Pang Wei Koh, and Bryan Kian Hsiang Low.
In Proceedings of the 2024 Empirical Methods in Natural Language Processing (EMNLP-24) Findings, Miami, Florida, Nov. 12-16, 2024.
Abstract |Slides | Cite (Bibtex)
This position paper proposes a data-centric viewpoint of AI research, focusing on large language models (LLMs). We start by making the key observation that data is instrumental in the developmental (e.g., pretraining and fine-tuning) and inferential stages (e.g., in-context learning) of LLMs, and yet it receives disproportionally low attention from the research community. We identify four specific scenarios centered around data, covering data-centric benchmarks and data curation, data attribution, knowledge transfer, and inference contextualization. In each scenario, we underscore the importance of data, highlight promising research directions, and articulate the potential impacts on the research community and, where applicable, the society as a whole. For instance, we advocate for a suite of data-centric benchmarks tailored to the scale and complexity of data for LLMs. These benchmarks can be used to develop new data curation methods and document research efforts and results, which can help promote openness and transparency in AI and LLM research.
@inproceedings{xu2024datacentricaiagelarge, title = "Position Paper: Data-Centric {AI} in the Age of Large Language Models", author = "Xu, Xinyi and Wu, Zhaoxuan and Qiao, Rui and Verma, Arun and Shu, Yao and Wang, Jingtan and Niu, Xinyuan and He, Zhenfeng and Chen, Jiangwei and Zhou, Zijian and Lau, Gregory Kang Ruey and Dao, Hieu and Agussurja, Lucas and Sim, Rachael Hwee Ling and Lin, Xiaoqiang and Hu, Wenyang and Dai, Zhongxiang and Koh, Pang Wei and Low, Bryan Kian Hsiang", booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2024", year = "2024", pages = "11895--11913", } -
Distributionally Robust Data Valuation .
Xiaoqiang Lin, Xinyi Xu, Zhaoxuan Wu, See-Kiong Ng and Bryan Kian Hsiang Low.
In Proceedings of the 41st International Conference on Machine Learning (ICML-24), Vienna, Austria, Jul. 21-27, 2024.
Acceptance rate (27.5%). Abstract |Code |Poster |Slides | Cite (Bibtex)
Data valuation quantifies the contribution of each data point to the performance of a machine learning model. Existing works typically define the value of data by its improvement of the validation performance of the trained model. However, this approach can be impractical to apply in collaborative machine learning and data marketplace since it is difficult for the parties/buyers to agree on a common validation dataset or determine the exact validation distribution a priori. To address this, we propose a distributionally robust data valuation approach to perform data valuation without known/fixed validation distributions. Our approach defines the value of data by its improvement of the distributionally robust generalization error (DRGE), thus providing a worst-case performance guarantee without a known/fixed validation distribution. However, since computing DRGE directly is infeasible, we propose using model deviation as a proxy for the marginal improvement of DRGE (for kernel regression and neural networks) to compute data values. Furthermore, we identify a notion of uniqueness where low uniqueness characterizes low-value data. We empirically demonstrate that our approach outperforms existing data valuation approaches in data selection and data removal tasks on real-world datasets (e.g., housing price prediction, diabetes hospitalization prediction).
@inproceedings{lin2024, title = {Distributionally Robust Data Valuation}, author = {Lin, Xiaoqiang and Xu, Xinyi and Wu, Zhaoxuan and Ng, See-Kiong and Low, Bryan Kian Hsiang}, booktitle = {Proceedings of the 41st International Conference on Machine Learning}, pages = {30362--30391}, year = {2024}, } -
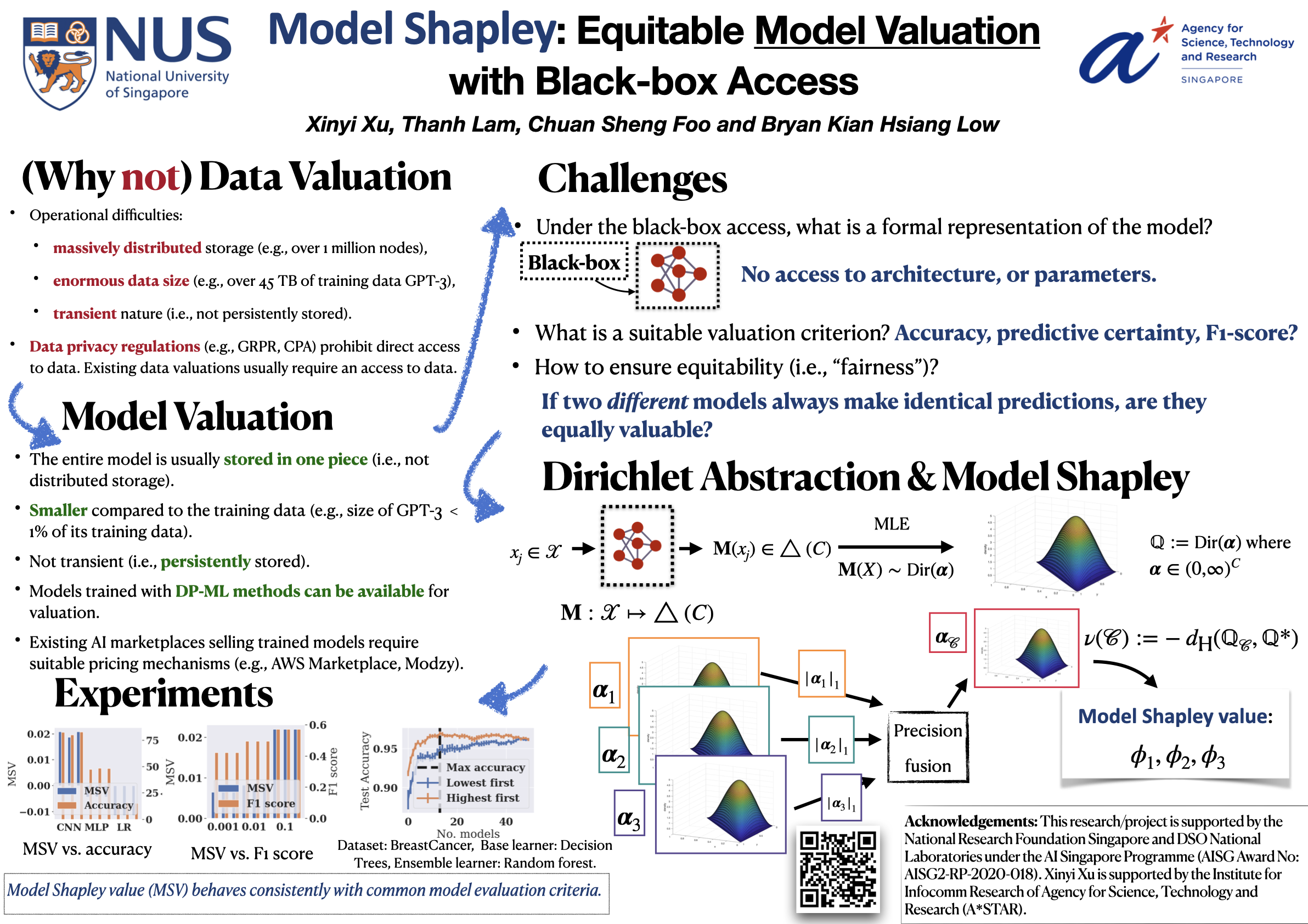
Model Shapley: Equitable Model Valuation with Black-box Access .
Xinyi Xu, Thanh Lam, Chuan-Sheng Foo, and Bryan Kian Hsiang Low.
In Advances in Neural Information Processing Systems 36: 37th Annual Conference on Neural Information Processing Systems (NeurIPS'23), New Orleans, U.S., Dec. 10-16, 2023.
Acceptance rate (26%). Abstract |Code |Poster |Slides | Cite (Bibtex)
Valuation methods of data and machine learning (ML) models are essential to the establishment of AI marketplaces. Importantly, certain practical considerations (e.g., operational constraints, legal restrictions) favor the use of model valuation over data valuation. Also, existing marketplaces that involve trading of pre-trained ML models call for an equitable model valuation method to price them. In particular, we investigate the black-box access setting which allows querying a model (to observe predictions) without disclosing model-specific information (e.g., architecture and parameters). By exploiting a Dirichlet abstraction of a model's predictions, we propose a novel and equitable model valuation method called model Shapley. We also leverage a formal connection between the similarity in models and that in model Shapley values (MSVs) to devise a learning approach for predicting MSVs of many vendors' models (e.g., 150) in a large-scale marketplace. We perform extensive empirical validation on the effectiveness of model Shapley using various real-world datasets and heterogeneous model types.
@inproceedings{xu2023model, title={Model Shapley: Equitable Model Valuation with Black-box Access}, author={Xinyi Xu and Thanh Lam and Chuan-Sheng Foo and Bryan Kian Hsiang Low}, booktitle={Thirty-seventh Conference on Neural Information Processing Systems}, year={2023}} -
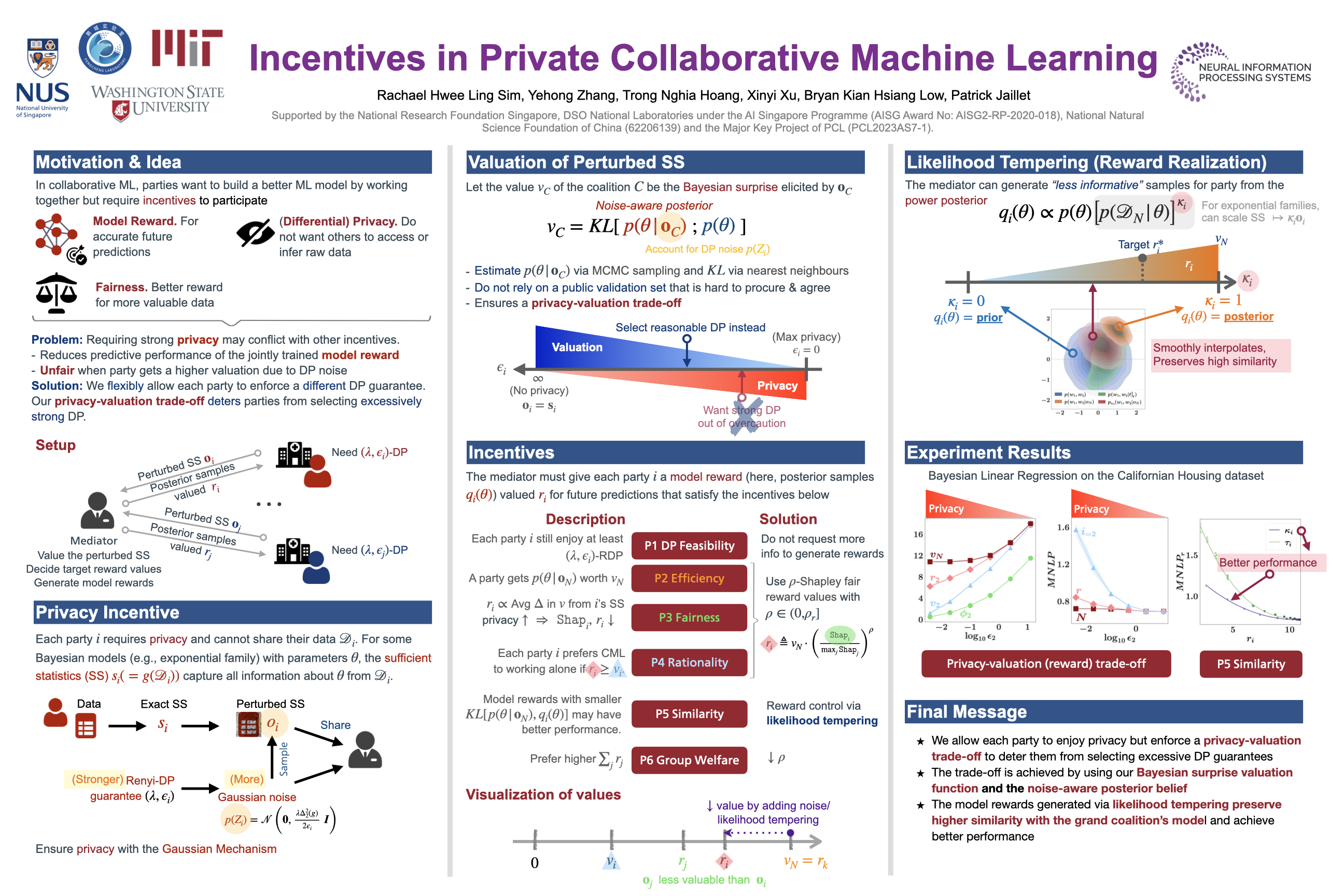
Incentives in Private Collaborative Machine Learning .
Rachael Hwee Ling Sim, Yehong Zhang, Trong Nghia Hoang, Xinyi Xu, Bryan Kian Hsiang Low, and Patrick Jaillet.
In Advances in Neural Information Processing Systems 36: 37th Annual Conference on Neural Information Processing Systems (NeurIPS'23), New Orleans, U.S., Dec. 10-16, 2023.
Acceptance rate (26%). Abstract |Code |Poster | Cite (Bibtex)
Collaborative machine learning involves training models on data from multiple parties but must incentivize their participation. Existing data valuation methods fairly value and reward each party based on shared data or model parameters but neglect the privacy risks involved. To address this, we introduce differential privacy (DP) as an incentive. Each party can select its required DP guarantee and perturb its sufficient statistic (SS) accordingly. The mediator values the perturbed SS by the Bayesian surprise it elicits about the model parameters. As our valuation function enforces a privacy-valuation trade-off, parties are deterred from selecting excessive DP guarantees that reduce the utility of the grand coalition's model. Finally, the mediator rewards each party with different posterior samples of the model parameters. Such rewards still satisfy existing incentives like fairness but additionally preserve DP and a high similarity to the grand coalition's posterior. We empirically demonstrate the effectiveness and practicality of our approach on synthetic and real-world datasets.
@inproceedings{sim2023incentives, title={Incentives in Private Collaborative Machine Learning}, author={Rachael Hwee Ling Sim and Yehong Zhang and Trong Nghia Hoang and Xinyi Xu and Bryan Kian Hsiang Low and Patrick Jaillet}, booktitle={Thirty-seventh Conference on Neural Information Processing Systems}, year={2023}} -
Collaborative Causal Inference with Fair Incentives .
Rui Qiao, Xinyi Xu, and Bryan Kian Hsiang Low.
In Proceedings of the 40th International Conference on Machine Learning (ICML-23), Hawaii, U.S., Jul. 23-29, 2023.
(Acceptance rate: 28%). Abstract |Code |Poster | Cite (Bibtex)
Collaborative causal inference (CCI) aims to improve the estimation of the causal effect of treatment variables by utilizing data aggregated from multiple self-interested parties. Since their source data are valuable proprietary assets that can be costly or tedious to obtain, every party has to be incentivized to be willing to contribute to the collaboration, such as with a guaranteed fair and sufficiently valuable reward (than performing causal inference on its own). This paper presents a reward scheme designed using the unique statistical properties that are required by causal inference to guarantee certain desirable incentive criteria (e.g., fairness, benefit) for the parties based on their contributions. To achieve this, we propose a data valuation function to value parties’ data for CCI based on the distributional closeness of its resulting treatment effect estimate to that utilizing the aggregated data from all parties. Then, we show how to value the parties’ rewards fairly based on a modified variant of the Shapley value arising from our proposed data valuation for CCI. Finally, the Shapley fair rewards to the parties are realized in the form of improved, stochastically perturbed treatment effect estimates. We empirically demonstrate the effectiveness of our reward scheme using simulated and real-world datasets.
@inproceedings{qiao2023, title = {Collaborative Causal Inference with Fair Incentives}, author = {Qiao, Rui and Xu, Xinyi and Low, Bryan Kian Hsiang}, booktitle = {Proceedings of the 40th International Conference on Machine Learning}, pages = {28300--28320}, year = {2023}} -
Fair yet Asymptotically Equal Collaborative Learning .
Xiaoqiang Lin*, Xinyi Xu*, See-Kiong Ng, Chuan Sheng Foo, and Bryan Kian Hsiang Low.
In Proceedings of the 40th International Conference on Machine Learning (ICML-23), Hawaii, U.S., Jul. 23-29, 2023.
(Acceptance rate: 28%). Abstract |Code |Poster | Cite (Bibtex)
In collaborative learning with streaming data, nodes (e.g., organizations) jointly and continuously learn a machine learning (ML) model by sharing the latest model updates computed from their latest streaming data. For the more resourceful nodes to be willing to share their model updates, they need to be fairly incentivized. This paper explores an incentive design that guarantees fairness so that nodes receive rewards commensurate to their contributions. Our approach leverages an explore-then-exploit formulation to estimate the nodes’ contributions (i.e., exploration) for realizing our theoretically guaranteed fair incentives (i.e., exploitation). However, we observe a “rich get richer” phenomenon arising from the existing approaches to guarantee fairness and it discourages the participation of the less resourceful nodes. To remedy this, we additionally preserve asymptotic equality, i.e., less resourceful nodes achieve equal performance eventually to the more resourceful/“rich” nodes. We empirically demonstrate in two settings with real-world streaming data: federated online incremental learning and federated reinforcement learning, that our proposed approach outperforms existing baselines in fairness and learning performance while remaining competitive in preserving equality.
@inproceedings{lin23, title = {Fair yet Asymptotically Equal Collaborative Learning}, author = {Lin, Xiaoqiang and Xu, Xinyi and Ng, See-Kiong and Foo, Chuan-Sheng and Low, Bryan Kian Hsiang}, booktitle = {Proceedings of the 40th International Conference on Machine Learning}, pages = {21223--21259}, year = {2023}} -
FAIR: Fair Collaborative Active Learning with Individual Rationality for Scientific Discovery .
Xinyi Xu, Zhaoxuan Wu, Arun Verma, Chuan Sheng Foo, and Bryan Kian Hsiang Low.
In Proceedings of the 26th International Conference on Artificial Intelligence and Statistics (AISTATS-23), Valencia, Spain, Apr. 25-27, 2023.
(Acceptance rate: 29%). Abstract |Code |Poster | Cite (Bibtex)
Scientific discovery aims to find new patterns and test specific hypotheses by analysing large-scale experimental data. However, various practical limitations, like high experimental costs or the inability to do some experiments, make it challenging for researchers to collect sufficient experimental data for successful scientific discovery. To this end, we propose a framework named \emph{collaborative active learning} (CAL) that enables researchers to share their experimental data for mutual benefit. Specifically, our proposed coordinated acquisition function sets out to achieve \emph{individual rationality} and \emph{fairness} so that everyone can equitably benefit from collaboration. Finally, we empirically demonstrate that our method outperforms existing batch active learning methods adapted to the CAL setting in terms of both learning performance and fairness on various real-world scientific discovery datasets (biochemistry, material science, and physics).
@inproceedings{xu23, title = {FAIR: Fair Collaborative Active Learning with Individual Rationality for Scientific Discovery}, author = {Xu, Xinyi and Wu, Zhaoxuan and Verma, Arun and Foo, Chuan Sheng and Low, Bryan Kian Hsiang}, booktitle = {Proceedings of The 26th International Conference on Artificial Intelligence and Statistics}, pages = {4033--4057}, year = {2023}}Probably Approximate Shapley Fairness with Applications in Machine Learning .
Zijian Zhou*, Xinyi Xu*, Rachael Hwee Ling Sim, Chuan Sheng Foo, and Bryan Kian Hsiang Low.
In Proceedings of the 37th AAAI Conference on Artificial Intelligence (AAAI-23), Oral Presentation, Washington D.C., U.S., Feb. 7-14, 2023.
(Acceptance rate: 19.6%). Abstract |Code |Talk |Slides | Cite (Bibtex)
The Shapley value (SV) is adopted in various scenarios in machine learning (ML), including data valuation, agent valuation, and feature attribution, as it satisfies their fairness requirements. However, as exact SVs are infeasible to compute in practice, SV estimates are approximated instead. This approximation step raises an important question: do the SV estimates preserve the fairness guarantees of exact SVs? We observe that the fairness guarantees of exact SVs are too restrictive for SV estimates. Thus, we generalise Shapley fairness to probably approximate Shapley fairness and propose fidelity score, a metric to measure the variation of SV estimates, that determines how probable the fairness guarantees hold. Our last theoretical contribution is a novel greedy active estimation (GAE) algorithm that will maximise the lowest fidelity score and achieve a better fairness guarantee than the de facto Monte-Carlo estimation. We empirically verify GAE outperforms several existing methods in guaranteeing fairness while remaining competitive in estimation accuracy in various ML scenarios using real-world datasets.
@inproceedings{Zhou2023, author = {Zhou, Zijian and Xu, Xinyi and Sim, Rachael Hwee Ling and Foo, Chuan Sheng and Low, Bryan Kian Hsiang}, title = {Probably approximate {S}hapley fairness with applications in machine learning}, year = {2023}, booktitle = {Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence and Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence and Thirteenth Symposium on Educational Advances in Artificial Intelligence} }On the Convergence of the Shapley Value in Parametric Bayesian Learning Games .
Lucas Agussurja, Xinyi Xu, and Bryan Kian Hsiang Low.
In Proceedings of the 39th International Conference on Machine Learning (ICML-22), Baltimore, U.S., Jul. 17-23, 2022.
(Acceptance rate: 21.9%). Abstract |Code |Talk | Cite (Bibtex)
Measuring contributions is a classical problem in cooperative game theory where the Shapley value is the most well-known solution concept. In this paper, we establish the convergence property of the Shapley value in parametric Bayesian learning games where players perform a Bayesian inference using their combined data, and the posterior-prior KL divergence is used as the characteristic function. We show that for any two players, under some regularity conditions, their difference in Shapley value converges in probability to the difference in Shapley value of a limiting game whose characteristic function is proportional to the log-determinant of the joint Fisher information. As an application, we present an online collaborative learning framework that is asymptotically Shapley-fair. Our result enables this to be achieved without any costly computations of posterior-prior KL divergences. Only a consistent estimator of the Fisher information is needed. The effectiveness of our framework is demonstrated with experiments using real-world data.
@inproceedings{Agussurja22, title = {On the Convergence of the Shapley Value in Parametric {B}ayesian Learning Games}, author = {Agussurja, Lucas and Xu, Xinyi and Low, Bryan Kian Hsiang}, booktitle = {Proceedings of the 39th International Conference on Machine Learning}, pages = {180--196}, year = {2022}}Data Valuation in Machine Learning: "Ingredients", Strategies, and Open Challenges .
Rachael Hwee Ling Sim*, Xinyi Xu*, and Bryan Kian Hsiang Low.
In Proceedings of the 31st International Joint Conference on Artificial Intelligence (IJCAI-22), Vienna, Austria, Jul. 23-29, 2022.
(Acceptance rate: 18.2%). Abstract |Talk (1 min) |Talk (12 mins) |Slides | Cite (Bibtex)
Data valuation in machine learning (ML) is an emerging research area that studies the worth of data in ML. Data valuation is used in collaborative ML to determine a fair compensation for every data owner and in interpretable ML to identify the most responsible, noisy, or misleading training examples. This paper presents a comprehensive technical survey that provides a new formal study of data valuation in ML through its “ingredients” and the corresponding properties, grounds the discussion of common desiderata satisfied by existing data valuation strategies on our proposed ingredients, and identifies open research challenges for designing new ingredients, data valuation strategies, and cost reduction techniques.
@inproceedings{Sim2022, title = {Data Valuation in Machine Learning: "Ingredients", Strategies, and Open Challenges}, author = {Sim, Rachael Hwee Ling and Xu, Xinyi and Low, Bryan Kian Hsiang}, booktitle = {Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, {IJCAI-22}}, pages = {5607--5614}, year = {2022}, note = {Survey Track}, }Incentivizing Collaboration in Machine Learning via Synthetic Data Rewards .
Sebastian Sheng Hong Tay, Xinyi Xu, Chuan Sheng Foo, and Bryan Kian Hsiang Low.
In Proceedings of the 36th AAAI Conference on Artificial Intelligence (AAAI-22) Oral Presentation, Feb. 22-Mar. 1, 2022.
(Acceptance rate: 4%). Abstract |Code |Talk | Cite (Bibtex)
This paper presents a novel collaborative generative modeling (CGM) framework that incentivizes collaboration among self-interested parties to contribute data to a pool for training a generative model (e.g., GAN), from which synthetic data are drawn and distributed to the parties as rewards commensurate to their contributions. Distributing synthetic data as rewards (instead of trained models or money) offers task- and model-agnostic benefits for downstream learning tasks and is less likely to violate data privacy regulation. To realize the framework, we firstly propose a data valuation function using maximum mean discrepancy (MMD) that values data based on its quantity and quality in terms of its closeness to the true data distribution and provide theoretical results guiding the kernel choice in our MMD-based data valuation function. Then, we formulate the reward scheme as a linear optimization problem that when solved, guarantees certain incentives such as fairness in the CGM framework. We devise a weighted sampling algorithm for generating synthetic data to be distributed to each party as reward such that the value of its data and the synthetic data combined matches its assigned reward value by the reward scheme. We empirically show using simulated and real-world datasets that the parties' synthetic data rewards are commensurate to their contributions.
@inproceedings{Tay2022, title={Incentivizing Collaboration in Machine Learning via Synthetic Data Rewards}, booktitle={Proceedings of the AAAI Conference on Artificial Intelligence}, author={Tay, Sebastian Shenghong and Xu, Xinyi and Foo, Chuan Sheng and Low, Bryan Kian Hsiang}, year={2022}, pages={9448-9456}}Gradient Driven Rewards to Guarantee Fairness in Collaborative Machine Learning .
Xinyi Xu*, Lingjuan Lyu*, Xingjun Ma, Chenglin Miao, Chuan Sheng Foo, and Bryan Kian Hsiang Low.
In Advances in Neural Information Processing Systems 34: 35th Annual Conference on Neural Information Processing Systems (NeurIPS'21) Dec. 6-14, 2021.
Acceptance rate (26%). Abstract |Code |Talk | Cite (Bibtex)
In collaborative machine learning(CML), multiple agents pool their resources(e.g., data) together for a common learning task. In realistic CML settings where the agents are self-interested and not altruistic, they may be unwilling to share data or model information without adequate rewards. Furthermore, as the data/model information shared by the agents may differ in quality, designing rewards which are fair to them is important so that they would not feel exploited nor discouraged from sharing. In this paper, we adopt federated learning as the CML paradigm, propose a novel cosine gradient Shapley value(CGSV) to fairly evaluate the expected marginal contribution of each agent’s uploaded model parameter update/gradient without needing an auxiliary validation dataset, and based on the CGSV, design a novel training-time gradient reward mechanism with a fairness guarantee by sparsifying the aggregated parameter update/gradient downloaded from the server as reward to each agent such that its resulting quality is commensurate to that of the agent’s uploaded parameter update/gradient. We empirically demonstrate the effectiveness of our fair gradient reward mechanism on multiple benchmark datasets in terms of fairness, predictive performance, and time overhead.
@inproceedings{Xu2021, author = {Xu, Xinyi and Lyu, Lingjuan and Ma, Xingjun and Miao, Chenglin and Foo, Chuan Sheng and Low, Bryan Kian Hsiang}, booktitle = {Advances in Neural Information Processing Systems}, title = {Gradient Driven Rewards to Guarantee Fairness in Collaborative Machine Learning}, volume = {34}, year = {2021}}Validation Free and Replication Robust Volume-based Data Valuation .
Xinyi Xu*, Zhaoxuan Wu*, Chuan Sheng Foo, and Bryan Kian Hsiang Low.
In Advances in Neural Information Processing Systems 34: 35th Annual Conference on Neural Information Processing Systems (NeurIPS'21) Dec. 6-14, 2021.
Acceptance rate (26%). Abstract |Code |Talk |Slides | Cite (Bibtex)
Data valuation arises as a non-trivial challenge in real-world use cases such as collaborative machine learning, federated learning, trusted data sharing, data marketplaces. The value of data is often associated with the learning performance (e.g., validation accuracy) of a model trained on the data, which introduces a close coupling between data valuation and validation. However, a validation set may notbe available in practice and it can be challenging for the data providers to reach an agreement on the choice of the validation set. Another practical issue is that of data replication: Given the value of some data points, a dishonest data provider may replicate these data points to exploit the valuation for a larger reward/payment. We observe that the diversity of the data points is an inherent property of a dataset that is independent of validation. We formalize diversity via the volume of the data matrix (i.e., determinant of its left Gram), which allows us to establish a formal connection between the diversity of data and learning performance without requiring validation. Furthermore, we propose a robust volume measure with a theoretical guarantee on the replication robustness by following the intuition that copying the same data points does not increase the diversity of data. We perform extensive experiments to demonstrate its consistency in valuation and practical advantages over existing baselines and show that our method is model- and task-agnostic and can be flexibly adapted to handle various neural networks.
@inproceedings{Xu2021a, author = {Xu, Xinyi and Wu, Zhaoxuan and Foo, Chuan Sheng and Low, Bryan Kian Hsiang}, booktitle = {Advances in Neural Information Processing Systems}, title = {Validation Free and Replication Robust Volume-based Data Valuation}, volume = {34}, year = {2021}}Journal and Workshop Papers
-
Collaborative Fairness in Federated Learning .
Lingjuan Lyu, Xinyi Xu, and Qian Wang.
In International Workshop on Federated Learning for User Privacy and Data Confidentiality in Conjunction (FL-IJCAI’20) Best Paper Award.
Abstract |Code | Cite (Bibtex)
In current deep learning paradigms, local training or the Standalone framework tends to result in overfitting and thus poor generalizability. This problem can be addressed by Distributed or Federated Learning (FL) that leverages a parameter server to aggregate model updates from individual participants. However, most existing Distributed or FL frameworks have overlooked an important aspect of participation: collaborative fairness. In particular, all participants can receive the same or similar models, regardless of their contributions. To address this issue, we investigate the collaborative fairness in FL, and propose a novel Collaborative Fair Federated Learning (CFFL) framework which utilizes reputation to enforce participants to converge to different models, thus achieving fairness without compromising the predictive performance. Extensive experiments on benchmark datasets demonstrate that CFFL achieves high fairness, delivers comparable accuracy to the Distributed framework, and outperforms the Standalone framework.
@Inbook{Lyu2020, author="Lyu, Lingjuan and Xu, Xinyi and Wang, Qian and Yu, Han", editor="Yang, Qiang and Fan, Lixin and Yu, Han", title="Collaborative Fairness in Federated Learning", bookTitle="Federated Learning: Privacy and Incentive", year="2020", publisher="Springer International Publishing", address="Cham", pages="189--204",} -
A Reputation Mechanism Is All You Need: Collaborative Fairness and Adversarial Robustness in Federated Learning .
Xinyi Xu and Lingjuan Lyu.
In International Workshop on Federated Learning for User Privacy and Data Confidentiality in Conjunction with ICML 2021 (FL-ICML’21) Oral Presentation.
Abstract |Code
Federated learning (FL) is an emerging practical framework for effective and scalable machine learning among multiple participants, such as end users, organizations and companies. However, most existing FL or distributed learning frameworks have not well addressed two important issues together: collaborative fairness and adversarial robustness (e.g. free-riders and malicious participants). In conventional FL, all participants receive the global model (equal rewards), which might be unfair to the high-contributing participants. Furthermore, due to the lack of a safeguard mechanism, free-riders or malicious adversaries could game the system to access the global model for free or to sabotage it. In this paper, we propose a novel Robust and Fair Federated Learning (RFFL) framework to achieve collaborative fairness and adversarial robustness simultaneously via a reputation mechanism. RFFL maintains a reputation for each participant by examining their contributions via their uploaded gradients (using vector similarity) and thus identifies non-contributing or malicious participants to be removed. Our approach differentiates itself by not requiring any auxiliary/validation dataset. Extensive experiments on benchmark datasets show that RFFL can achieve high fairness and is very robust to different types of adversaries while achieving competitive predictive accuracy.
-
Hierarchical Reinforcement Learning in StarCraft II with Human Expertise in Subgoals Selection .
Xinyi Xu, Tiancheng Huang, Pengfei Wei, Akshay Narayan, and Tze-Yun Leong.
In Workshop on Bridging the Gap Between AI Planning and Reinforcement Learning (PRL-2020).
Abstract |Code
This work is inspired by recent advances in hierarchical reinforcement learning (HRL) (Barto and Mahadevan 2003; Hengst 2010), and improvements in learning efficiency from heuristic-based subgoal selection, experience replay (Lin 1993; Andrychowicz et al. 2017), and task-based curriculum learning (Bengio et al. 2009; Zaremba and Sutskever 2014). We propose a new method to integrate HRL, experience replay and effective subgoal selection through an implicit curriculum design based on human expertise to support sample-efficient learning and enhance interpretability of the agent's behavior. Human expertise remains indispensable in many areas such as medicine (Buch, Ahmed, and Maruthappu 2018) and law (Cath 2018), where interpretability, explainability and transparency are crucial in the decision making process, for ethical and legal reasons. Our method simplifies the complex task sets for achieving the overall objectives by decomposing them into subgoals at different levels of abstraction. Incorporating relevant subjective knowledge also significantly reduces the computational resources spent in exploration for RL, especially in high speed, changing, and complex environments where the transition dynamics cannot be effectively learned and modelled in a short time. Experimental results in two StarCraft II (SC2) (Vinyals et al. 2017) minigames demonstrate that our method can achieve better sample efficiency than flat and end-to-end RL methods, and provides an effective method for explaining the agent's performance.
Book Chapters
-
Incentives in federated learning .
Rachael Hwee Ling Sim, Sebastian Shenghong Tay, Xinyi Xu, Yehong Zhang, Zhaoxuan Wu, Xiaoqiang Lin, See-Kiong Ng, Chuan-Sheng Foo, Patrick Jaillet, Trong Nghia Hoang, and Bryan Kian Hsiang Low.
In Lam M. Nguyen, Trong Nghia Hoang, Pin-Yu Chen, editors, Federated Learning - Theory and Practice, Chapter 16, pages 299-309. Elsevier, 2024.
Abstract
This chapter explores incentives to encourage clients to participate in FL and contribute more valuable data. Clients may be hesitant to participate and benefit others when they incur significant costs to collect data, compute model updates, and risk losing privacy. Incentivization addresses these concerns through three key components: fair contribution evaluation (CE) of each client’s data, client selection to maximize the utility of the global model, and reward allocation to clients. Intuitively, clients desire higher valued rewards which at least match their costs. These and other requirements will be formally described as incentives. Lastly, we will discuss some recent solutions and open problems to achieve these incentives in various settings, including the setting where the CE is declared vs. measured and the rewards are monetary vs. model-based.
-
Data valuation in federated learning .
Zhaoxuan Wu, Xinyi Xu, Rachael Hwee Ling Sim, Yao Shu, Xiaoqiang Lin, Lucas Agussurja, Zhongxiang Dai, See-Kiong Ng, Chuan-Sheng Foo, Patrick Jaillet, Trong Nghia Hoang, and Bryan Kian Hsiang Low.
In Lam M. Nguyen, Trong Nghia Hoang, Pin-Yu Chen, editors, Federated Learning - Theory and Practice, Chapter 15, pages 281-295. Elsevier, 2024.
Abstract
Federated learning (FL) is an emerging paradigm that enables collaborative machine learning (CML) with training data locally stored at the distributed clients. However, clients may still be reluctant to participate in the federated effort unless their contributions are accurately recognized and fairly compensated. Data valuation is thus extensively required to measure clients’ relative contributions. To this end, we first recall data valuation methods in the conventional supervised CML setting, followed by extensions to the FL paradigm. To better address the challenge that clients’ local data are unavailable to the server, we also discuss many specialized data valuation methods developed for both horizontal and vertical FL in detail. This chapter aims to provide a comprehensive suite of data valuation tools to empower FL practitioners in various scenarios.
-
Fairness in federated learning .
Xiaoqiang Lin, Xinyi Xu, Zhaoxuan Wu, Rachael Hwee Ling Sim, See-Kiong Ng, Chuan-Sheng Foo, Patrick Jaillet, Trong Nghia Hoang, and Bryan Kian Hsiang Low.
In Lam M. Nguyen, Trong Nghia Hoang, Pin-Yu Chen, editors, Federated Learning - Theory and Practice, Chapter 8, pages 143-158. Elsevier, 2024.
Abstract
Federated learning (FL) enables a form of collaboration among multiple clients in jointly learning a machine learning (ML) model without centralizing their local datasets. Like in any collaboration, it is imperative to guarantee fairness so that the clients are willing to participate. For instance, it is unfair if one client benefits significantly more than others, or if some client benefits disproportionately to its contribution in the collaboration. Additionally, it is also unfair if the ML model makes biased predictions against certain groups of clients. This chapter discusses three specific notions of fairness by highlighting their motivations from real-world use-cases, examining several specific definitions for each notion and lastly describing the corresponding algorithms proposed to achieve each notion of fairness. Lastly, this chapter summarizes the identified gaps in current research efforts into open problems.
-
Collaborative Fairness in Federated Learning .
Lingjuan Lyu, Xinyi Xu, Qian Wang, and Han Yu.
In Qiang Yang, Lixin Fan, and Han Yu, editors, Federated Learning - Privacy and Incentive, volume 12500 of Lecture Notes in Computer Science, pages 189–204. Springer, 2020.
Abstract |Code
In current deep learning paradigms, local training or the Standalone framework tends to result in overfitting and thus low utility. This problem can be addressed by Distributed or Federated Learning (FL) that leverages a parameter server to aggregate local model updates. However, all the existing FL frameworks have overlooked an important aspect of participation: collaborative fairness. In particular, all participants can receive the same or similar models, even the ones who contribute relatively less, and in extreme cases, nothing. To address this issue, we propose a novel Collaborative Fair Federated Learning (CFFL) framework which utilizes reputations to enforce participants to converge to different models, thus ensuring fairness and accuracy at the same time. Extensive experiments on benchmark datasets demonstrate that CFFL achieves high fairness and performs comparably to the Distributed framework and better than the Standalone framework.
Professional Services
- Reviewer for NFFL 2021 (federated learning workshop at NeurIPS'21), ICLR 2024 Workshop (Me-FoMo), ICML 2022-2024, NeurIPS 2022-2024, ICLR 2023-2025, AAMAS 2023-2025, AISTATS 2023 2024, AAAI 2024 2025, IJCAI 2024 (main and survey tracks).
- Post-conference Workshop Proposal Reviewer for ICML 2024.
- Top Reviewer (Top 10%) for AISTATS 2023.
- Outstanding Reviewer (Top 10%) for ICML 2022.
- Top Reviewer for NeurIPS 2022, 2023.
Honors & Awards
- 2010 - 2014. School-based Scholarship (formerly SM1 scholarship) of Ministry of Education, Singapore, at Hwa Chong Institution high school & junior college.
- 2015 - 2020. Science and Technology Scholarship of NUS, Singapore, as an undergraduate at NUS.
- 2020 - present. A*STAR Computing and Information Science (ACIS) Scholarship of Agency for Science, Technology and Research (A*STAR), as a Ph.D. research student in School of Computing, NUS.
- 2020/21 Semester 2. Honor List of Student Tutor, School of Computing, NUS.
- 2021/22 Semester 1. Research Achievement Award of School of Computing, NUS.
- 2022. 1 of 5 CS Ph.D. students nominated for the Apple Scholars in AI/ML 2023 Ph.D. Fellowship, by School of Computing, NUS.
- 2023/24. 1 of 5 CS Ph.D. students for Teaching Fellowship Scheme by School of Computing, NUS.
- 2023/24 Semester 1. Research Achievement Award of School of Computing, NUS.
- 2023/24 Semester 2. 1 of 11 recipients of Dean's Graduate Research Excellence Award of School of Computing, NUS.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}